Data Flows – The Python Script Operator and why you should avoid it
When using SAP Datasphere to transform data for persistence, the Data Flow provides the necessary functionality. We recently compared various basic transformation tasks using different modeling approaches. Therefore, we tried four different approaches to implement a certain logic:
- 1. Modelling with the Standard Operators in the Data Flow
- 2. Modelling with a Graphical View as a source to be consumed in the Data Flow
- 3. Modelling with a SQL View as a source to be consumed in the Data Flow
- 4. Modelling with the Script Operator in the Data Flow.
The goal was to give a recommendation about what approach might be the best for various scenarios in case of runtime, maintenance, other categories and if every scenario can even be modelled with every approach. We implemented the following scenarios:
- String to Date Conversion
- Join Data
- Concatenate Columns
- Aggregate Data
- Transpose Data and Aggregate
- Regex
- Unnesting Data
- Generate a Hash
- Generate a Rank Column
- Calculate a moving Average
Setup
To have a comparable setup, we performed this action with an identical dataset, which contains the following columns:
- Region
- Country
- Item Type
- Sales Channel
- Order Priority
- Order Date
- Order ID
- Ship Date
- Unit Sold
- Unit Price
We uploaded this dataset (a CSV file) into a table. The table then contained 10 million records. The reason for that is that we wanted to get a feeling how Data Flows and Datasphere handles big amounts of data.
Results and Interpretation
The outcome of our tests is now displayed in the table below. Note that the runtimes are displayed in MM:SS format, with seconds rounded to minutes if the runtime exceeds a few minutes.
| Scenario | Python (Script Operator) | Standard Operator | Graphical View | SQL View |
| String to Date | 45:00 | 00:45 | 00:58 | 00:49 |
| Join | NA | 01:00 | 00:53 | 00:50 |
| Concatenate | 36:00 | 00:52 | 00:51 | 00:36 |
| Aggregation | 23:00 | 00:39 | 00:25 | 00:37 |
| Transpose and Aggregation | 24:00 | 00:50 | 00:28 | 00:24 |
| Regex | 36:00 | 00:59 | 01:00 | 00:50 |
| Unnesting Data | 14:00 | NA | NA | 00:38 |
| Hash | 234:00 | NA | 01:00 | 01:00 |
| Rank | 40:00 | NA | 00:58 | 01:00 |
| Moving Averages | 23:00 | NA | NA | 00:21 |
For better comparison, the chart below provides an overview in logarithmic scale.
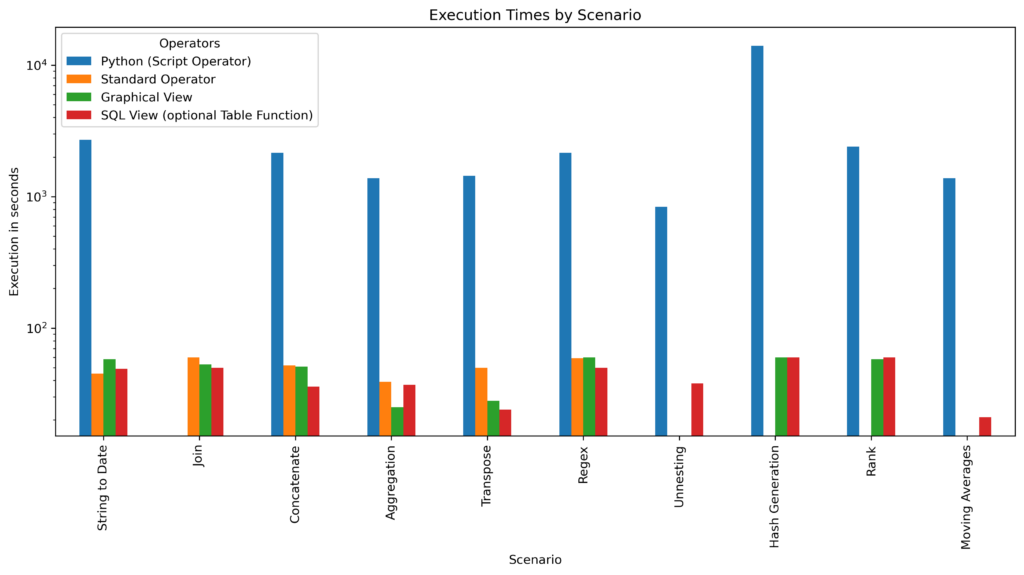
One of the first findings is that between the Standard Operator, the Graphical View and the SQL View there is not a huge difference. Given the amount of data, the performance is overall quite pleasant.
Additionally, some requirements or tasks are not feasible with the Standard Operator or the Graphical View, but an SQL View supports a wide range of possibilities.
The elephant in the room is obviously the performance of the Script Operator. The one thing which should enhance your possibilities as a developer with a currently very popular programming language does not perform in any acceptable way compared to the other options. After we did our tests, we contacted SAP support to verify one of our scenarios. We thought we missed something in our modelling approach or probably this is even a bug. Maybe we missed the “Make it fast” setting. But after we posted our incident, we got some insight from SAP Support why this is slow. Spoiler alert: We did not miss the “Make it fast” setting. The explanation for this is quite simple. When you use the Standard Operators (without the Script Operator), the Graphical View or the SQL View everything can be performed directly on the database. However, when you use the Script Operator all the data which is processed in the Script Operator needs to be transferred to a separate SAP DI cluster which will perform the Python operation and afterwards the result needs to be transferred back. In our case that is 10 million records which is almost about 1GB of data. We tried to illustrate the process based on the feedback from SAP in the picture below on a high level.

Also, the recommendation by the support was that the Script Operator should only be used if the requirement cannot be implemented with one of the other options. However, we think that how the Script Operator is advertised by SAP this can be an unpleasant surprise. Currently we see the Script Operator to be used very carefully, because in the end it might be a bottle neck in processing data during a transformation. Now one could argue that 10 million records is not something which is transferred on a regular basis in data warehouses, but we think this statement is not correct. In current SAP BW Warehouses, we regularly see the amount of data which is growing. Transferring at least 1 million records daily is not uncommon. Initially we were very excited to used Python, but currently we would generally advise against its use unless absolutely necessary. Even then, be prepared for potential performance issues during the runtime of your Data Flows.
Conclusion
To reiterate, the primary takeaway is the recommendation to avoid using the Script Operator in a Dataflow. Due to our test and the incident we submitted to SAP, we gained insights into how the data is processed in the background. We also searched to find if SAP provides this information already somewhere within the Datasphere documentation but could not find it. This might be helpful to gain a better understanding. It might be slightly misleading how the Script Operator is advertised. It’s important to be aware of its limitations, making SQL the preferred option for now.