BW on HANA can easily enable SQL data access for third party tools, using the “External SAP HANA View” flag to automatically generate Calculation Views out of BW objects. However, Consuming multidimensional BW scenarios through relational SQL paradigm can lead to quite some issues with performance. This blog is about a few basic technical tips, which help to enhance runtime performance. Tested with BW 7.5 on HANA SPS 10, 11 and 12.
1. System Checks
SAP provides the “SQL Statement Collection for SAP HANA”, which you can download from SAP Note 1969700. You will get a zip file which can be imported and used within HANA Studio, for instructions see this blog.
The collection includes some quite useful database checks:
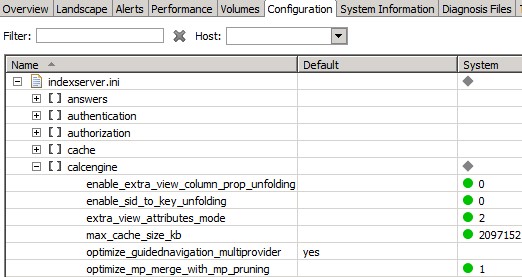
- As a starting point, you can execute the “MiniChecks” from within folder “Configuration”. The result indicates whether there is an issue you should look into more closely and it also points to the appropriate documentation. Further information how to interpret the results can be found in SAP Note 1999993.
- Folder “SQL” gives performance related information like historic expensive statements and plan cache usage.
- The Folders “BW” and “Tables” include some basic checks to make sure there are no inconsistencies or other issues related to your tables.
2. Table Maintenance
Check and correct table issues
- In addition to the checks via HANA Studio there is also the very useful report RSDU_TABLE_CONSISTENCY, which identifies and even fixes several HANA specific issues like inefficient indexes, partitioning or compression.
- First run the report in store mode, this will display a list with all the problems found. Now go through all the entries and mark them for repair via context menu. Finally, re-run the report in repair mode. Most issues can be fixed automatically, while a few may need additional manual care.
- SAP recommends running that report on a regular basis e.g. once a month.
Prefer column store instead of row store
-
- Column tables are optimized for query read access, feature advanced compression and can be partitioned and distributed through all nodes in scale-out environments.
- In contrast, row store tables are more suitable for write operations of full data records. However, they always reside on the master node, which can become a performance bottleneck. That is, because A) for row store traffic there is no load balancing in scale-out environments and B) the more space your row tables consume, the less free memory remains for calculations, which can potentially lead to out-of-memory errors.
- What’s more, there is an implication for the query execution plan, which you can display via HANA Studio “Explain Plan” feature. Most operations take place in column engine, however if you are using row store tables, then switches between execution engines are necessary, see screenshot below:
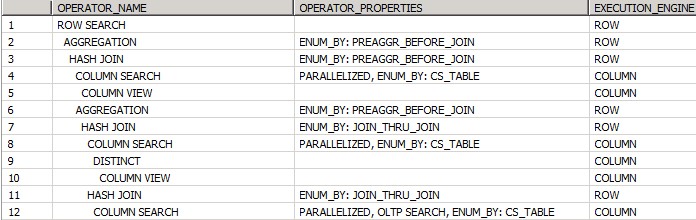
Problem is that whenever such engine switches occur, all the intermediate results have to be temporarily materialized, which is quite a performance disadvantage. Therefore, it is best practice to use only column tables.
Avoid Partitioning Issues
- Watch out the 2 billion rows limit when it comes to SID tables. If your tables exceed that size, they will have to be partitioned, and in case of SID tables this which will lead to performance drops.
- Be sure to run regular table distribution optimizations to balance the load on a scale-out system. This also prevents certain issues, like new / change / active DSO tables that are not kept together, which would lead to performance drops when loading or activation data.
- Consider using advanced tools like the Data Distribution Optimizer (see SAP Note 2092669)
Watch your indexes
- In general, there is always a trade-off with speed vs. memory consumption. Since HANA memory is expensive and indexes can grow quite large, you should avoid any that are not really necessary.
- If you cannot remove multi row indexes, you could try to reduce them to single column index.
- There is the option to convert indexes to inverted hash, which potentially consumes 30% less space. We have not tried this yet, so I cannot verify how well this works in the field.
3. Parameter Settings
There are some configuration settings that have a huge impact on performance. Therefore, it is important to make sure that the parameters in Administration Console -> Configuration are reasonably set.
- The following parameters improved both SQL performance and stability on our system:
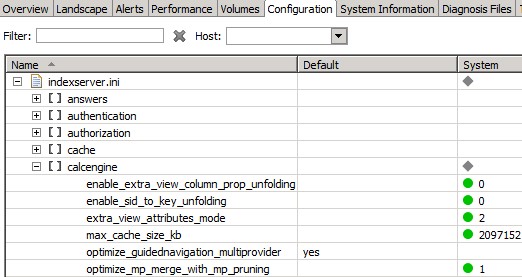
- This is just to give you an idea, please do not simply reuse all those exact settings. You will have to adjust all values according to your system size and setup. Additional recommendations are given in this blog.
- You can always use the following statement to display an overview about custom settings that have been modified from standard configuration:select * from sys.m_inifile_contents where layer_name = ‘SYSTEM’
4. Software Revision
We tested a lot of HANA revisions and also implemented quite a few hundred SAP Notes in BW backend lately. We can certainly say that the revision and patch level you are on makes a huge difference for SQL runtime performance.
- Obviously, always apply the latest BW Support Package and HANA revision if possible.
- When it comes to execution of external SAP HANA Views, there have been major improvement regarding unfolding in recent HANA revisions.
- Unfolding basically means that the basic elements and hence the execution plan for certain objects can be determined in more detail. So instead of executing just one single search operation on a View, the processing is distributed along multiple steps and engines. The screenshots below show the explain plans for the very same scenario, executed on different HANA revisions.
- SPS 11 – single search operation:
- SPS 12 – multiple operations and different engines:
- SPS 11 – single search operation:

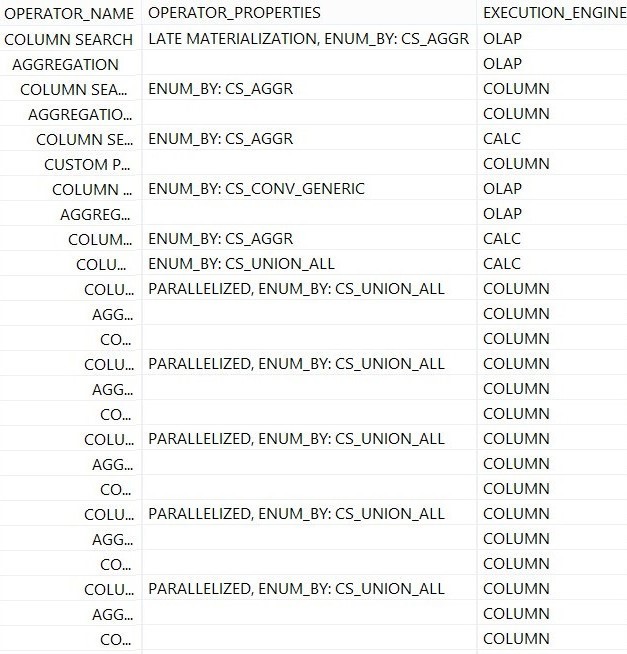
Some of our scenarios suddenly ran 2-3 times faster due to this.
https://blogs.sap.com/2017/06/29/hana-views-sql-technical-performance-optimization/


