DATA FLOWS IN SAP DATASPHERE (DSP) – Part 4: Using Dataspheres HANA Cloud Instance with Table Functions and how to integrate them seamlessly
Introduction
In the final part of this series, we want show how to use the HANA cloud instance and its functionalities and consume them within SAP Datasphere and Data Flows. Therefore, we want to show how it is possible to use the Predictive Analysis Library (PAL) and Automated Predictive Library (APL) functionalities of the underlying HANA instance and utilize it within SAP Datasphere.
Setup
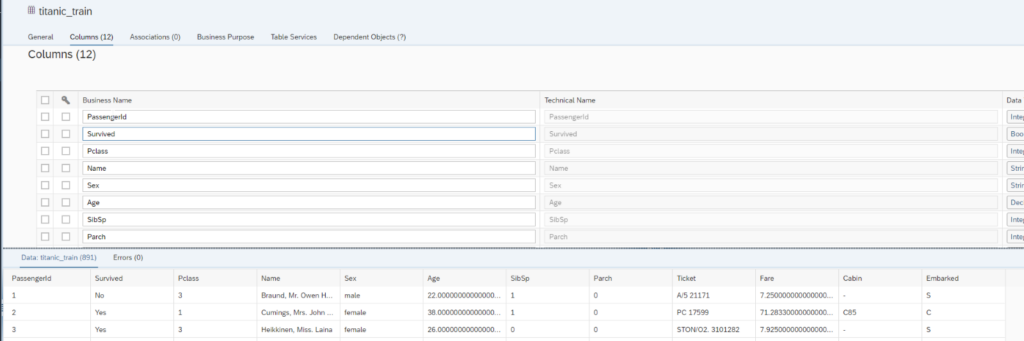
As a first step we upload the Train and Test data into our Datasphere Space. We use the well-known classification example from Kaggle predicting if a passenger will survive on the Titanic based on different features. For more information, please look at https://www.kaggle.com/c/titanic/data. Our table for training the model will contain the train data and we uploaded it into the table “titanic_train”.
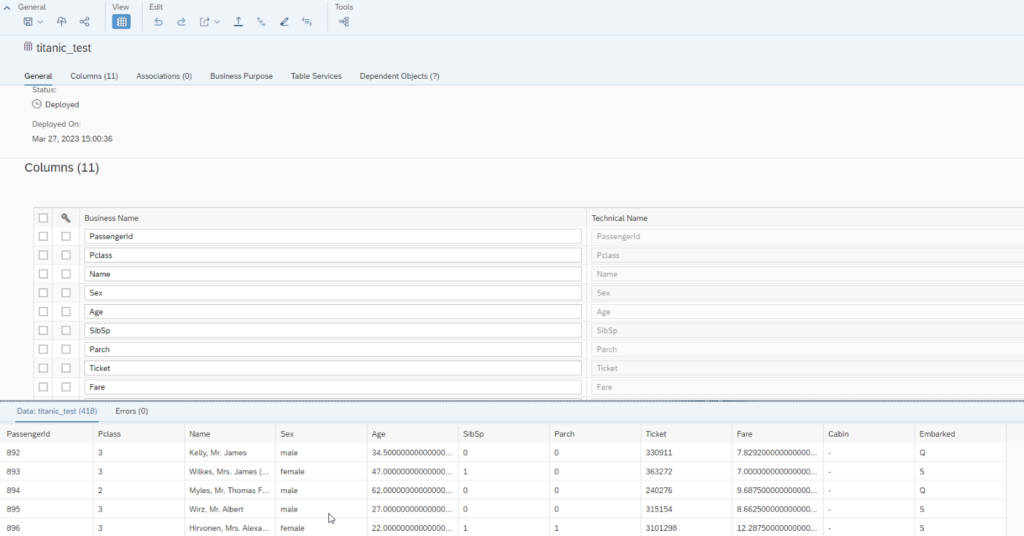
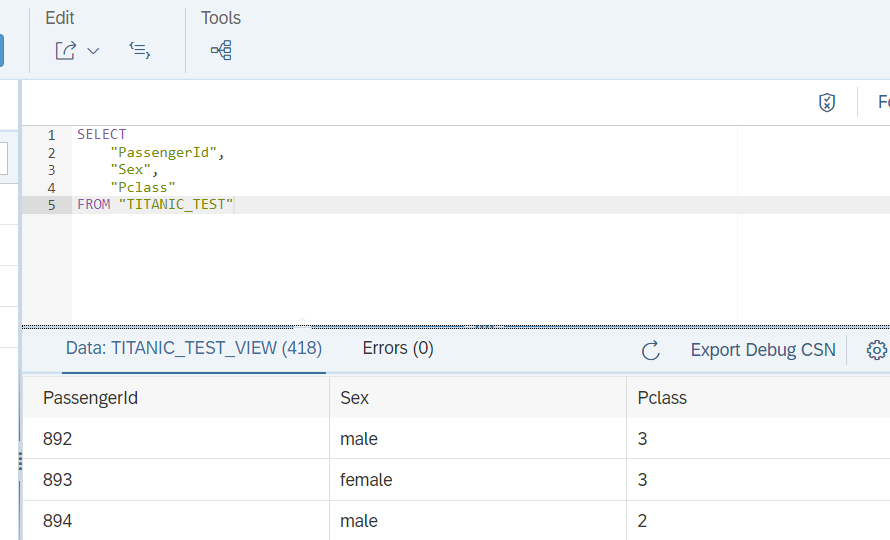
For the prediction at a later point we also upload the test data to the table “titanic_test”. You may notice the feature/dimension “Survived” is missing, which we will predict at a later point.
Now we also built on top of the table “train_test” a SQL view for consumption within the HANA instance. We will only use the features/dimensions Sex and Pclass for the prediction task.
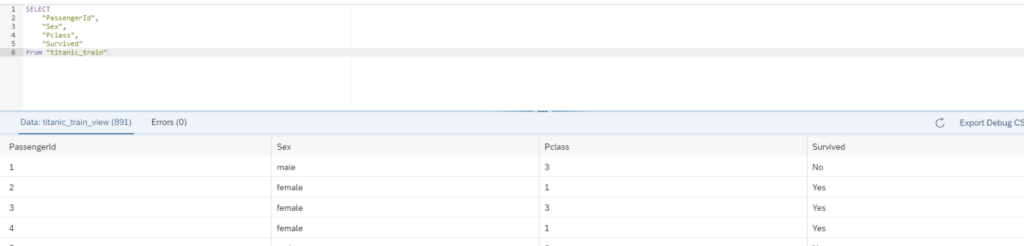
We also create a view for the test table:
In a next step it is necessary to create a DB User within our Space, which is described how to do that.

You also need to enable the user to be able to use the APL and PAL libraries. To enable these functionalities you need to follow the instructions followed in this SAP Note https://me.sap.com/notes/2994416/E.
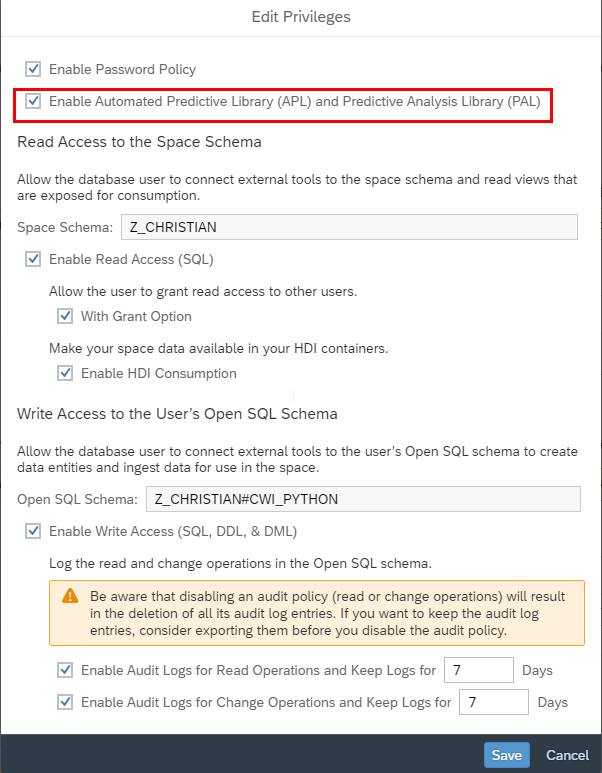
Database Objects and Integration to SAP Datasphere
We will use a classic Logistic Regression to predict weather a passenger survived or not. The documentation for this function you can find here https://help.sap.com/docs/SAP_HANA_PLATFORM/2cfbc5cf2bc14f028cfbe2a2bba60a50/46effe560ea74ecbbf43bab011f2acf8.html.
In the first step we create a Parameter Table, which defines which variables we will user for our model, which we will train in the next step. We only use the Sex and the Passenger Class to perform our prediction. The creation for this table looks like this:
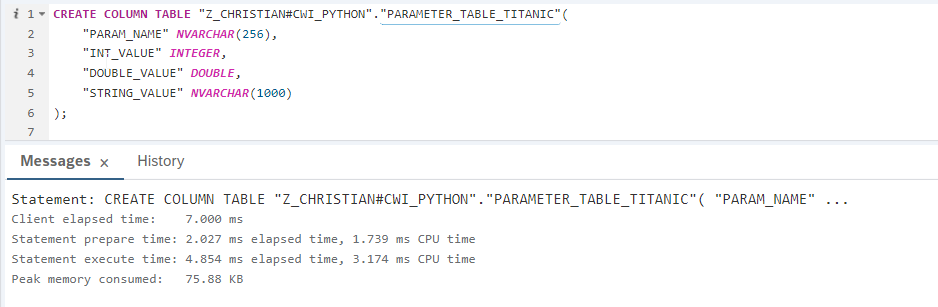
And the records then the following:

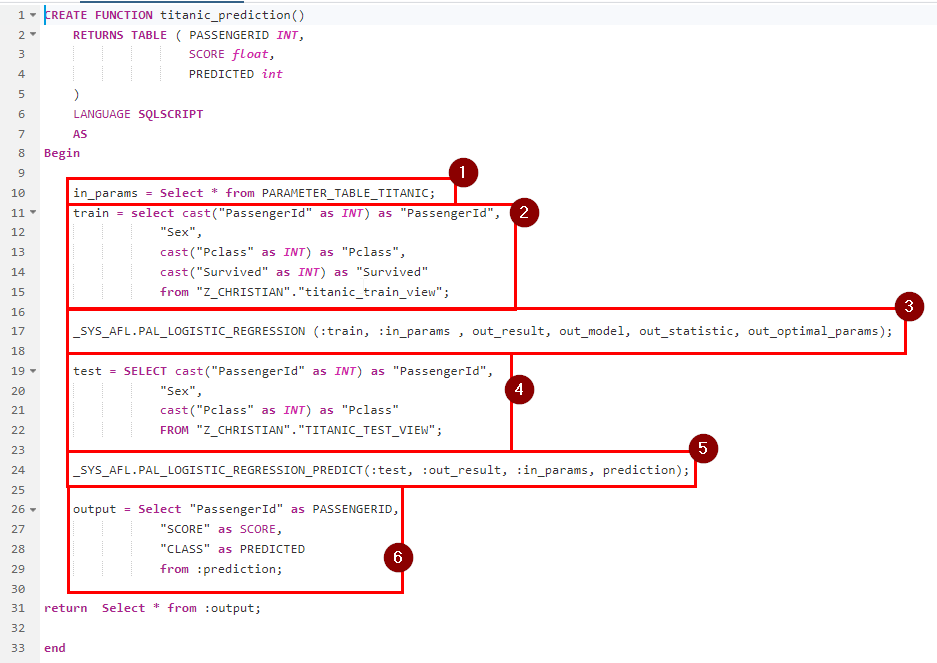
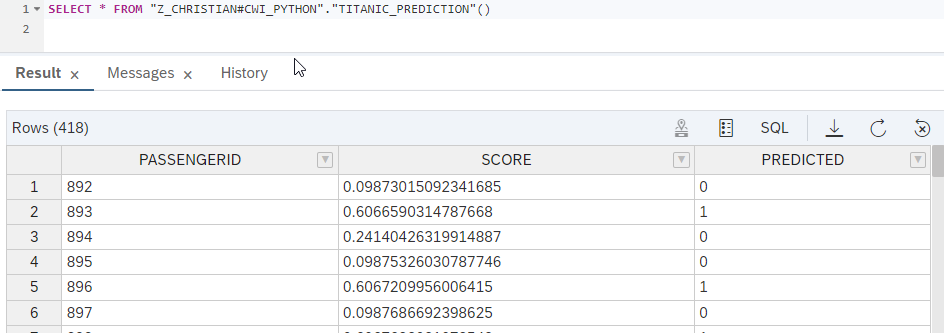
The output of this function gives us then the following values:
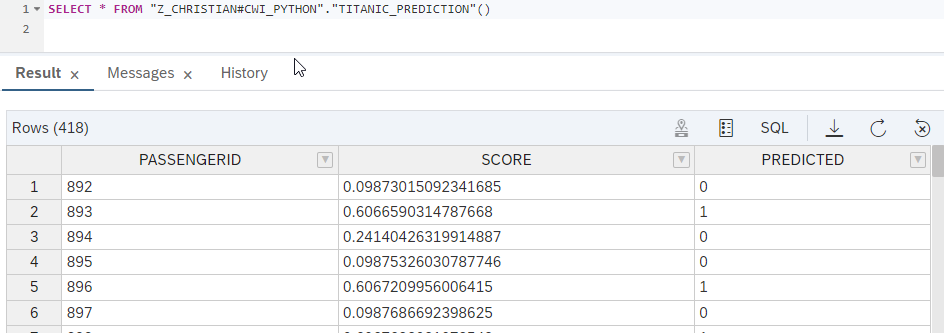
Now we also want to be able to integrate this data into the and to do this we built a view on top of this function.

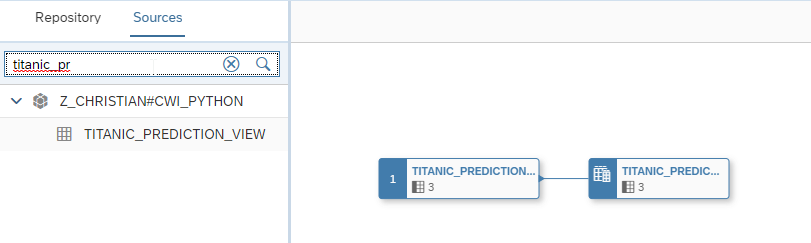
To do this we go into the Data Builder and create a new Graphical View. Within the Sources Panel we see now that the view is available within the schema. During the creation of this view, we are asked to import and deploy this table.
When we check now the tables properties we can see that the underlying source of this table is the before created view in the database. So we can utilize the predictive functionalities within SAP Datasphere objects.
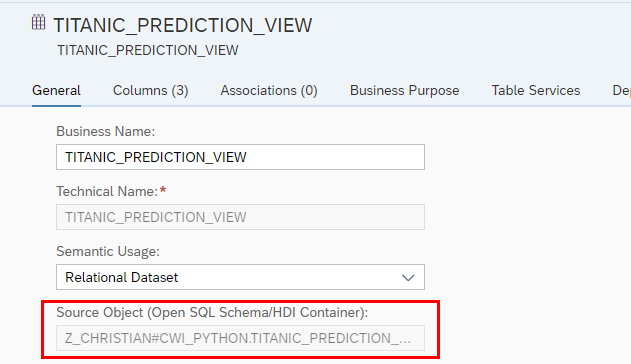
This comes in now handy so that you can integrate the above created view into a Data Flow again and use this as a source and enrich or transform it if required.
Conclusion
As you saw it is possible to use Table functions from the SAP libraries within SAP Datasphere. So, data which is stored within SAP Datasphere can be accessed via the database instance and already predefined functions can be applied and then be consumed in SAP Datasphere. Overall, this is an interesting functionality which will help in future to realize certain business requirements.