Disclaimer
SAP recently announced the launch of SAP Datasphere, which is the next generation of SAP Data Warehouse Cloud. Therefore, also the name from SAP Data Warehouse Cloud changed to SAP Datasphere. This blog, which was posted ahead of this change, refers to SAP Data Warehouse Cloud. Everything which is mentioned within the post is also true for SAP Datasphere.
Introduction
As SAP is following its “Cloud First” strategy it is inevitable to gain an understanding of Data Warehouse Cloud (DWC) if you are working in the analytics area. Therefore, we are closely following the development in this area and decided it is time to come up with a small blog series. In this series we want to focus on how Data Flows are working. Therefore, we decided to split this series in the following topics:
- 1/4 Data Flows in DWC – A brief Introduction into Data Flows
- 2/4 Data Flows in DWC – Comparing Performance – The Script Operator Performance vs SQL View Functions in Data Flows
- 3/4 Data Flows in DWC – Using SQL Table Functions and incorporate them into your Data Flow
- 4/4 Data Flows in DWC – Using DWCs HANA Cloud Instance with Table Functions and how to integrate them seamlessly
But maybe we are not finished after part 4 and keep going with new insights.
Data Flow Definition
A Data Flow is used as per SAP Definition (https://help.sap.com/docs/SAP_DATA_WAREHOUSE_CLOUD/c8a54ee704e94e15926551293243fd1d/e30fd1417e954577baae3246ea470c3f.html?locale=en-US) “to move and transform data in an intuitive graphical interface”. The Data Flow is created within the part of the Data Builder in DWC, and it currently supports the following operators to be used within your transformation process:
- Join Operator
- Union Operator
- Projection Operator
- Aggregation Operator
- Script Operator
As we are coming from a strong Business Warehouse background, we are always comparing things to the past. Which in our case would be a classical SAP BW on HANA or SAP BW/4HANA. We currently see the Data Flow as a substitute for what used to be in a BW system the transformation.
We decided therefore to show in this series a few small and very simple requirements we previously had to implement in BW with Transformations and now implement them with Data Flows.
Hint: We assume that you know the main components of DWC (Data Builder, Business Builder, Tables,…) and how to add tables or views in a Data Flow and therefore, will not show this in detail.
Example 1 – Field Look Up
A very common requirement is to look up field values during a Transformation from a different Data Provider. Previously this was probably done in a Transformation by:
- Looking up Masterdata and their Attributes via the Rule Details in the Field mapping
- Implementing a lookup in one of the Transformation Routines via ABAP or AMDP Script
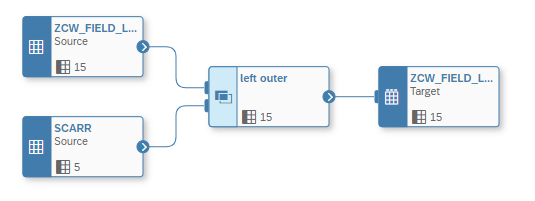
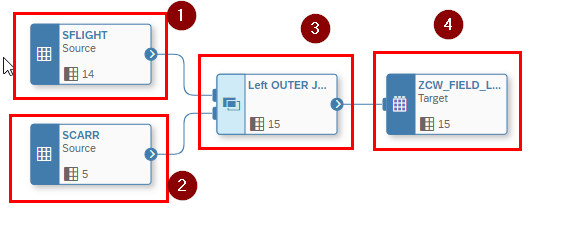
In DWC we realize this scenario by using the Join Operator. Our Use Case will use the well-known SAP’s flight and booking data. We want to add to the SFLIGHT data our (which includes Transaction Data) during the Data Flow the Carrier Name (CARRNAME).
Therefore, we perform the following steps:
- Add the Transaction Data SFLIGHT
- Add the Masterdata SCARR
- In Step 3 we define the Join Condition
- And we need to define a Target table
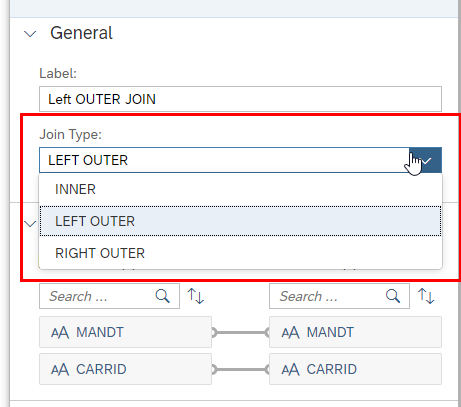
In the Join Operator we have 3 different Join Types:
- Inner
- Left Outer
- Right Outer
And also we need to map the fields for the Join Definition and can then add fields in the Columns section. With a click on the Info button also the source is displayed:
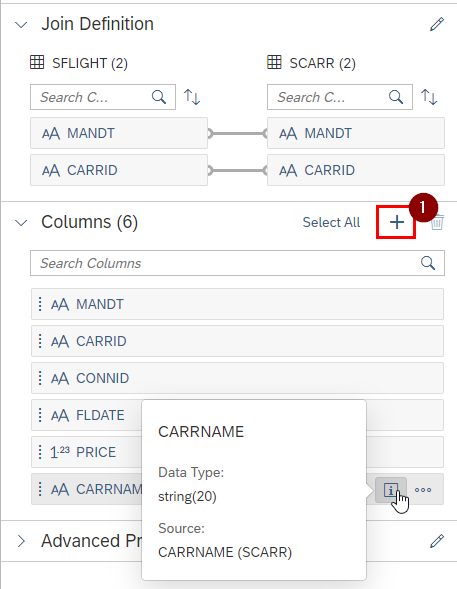
The last step is to add a target table and then the Data Flow can be saved and deployed and executed. The Monitoring then happens via the Data Flow Monitor, which we will talk about later.
Example 2 – Concatenate Field Values
For our second example we want to concatenate two values into one field during the Data Flow. For this exercise we will use the projection operator.
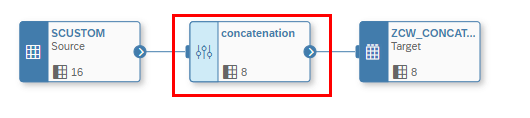
Within the Projection Operator it is possible to add “Calculated Columns” (1) which are then displayed with a formula sign (2).
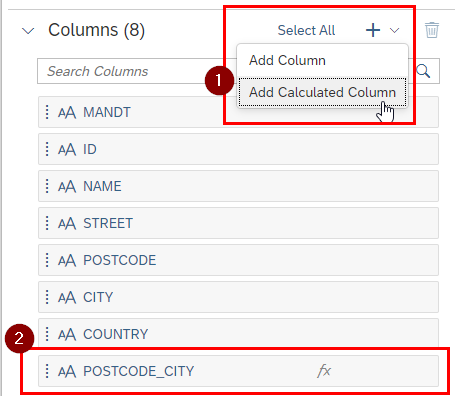
Like the Formula Interface in a Transformation, it is possible to use various functions. In our case we used CONCAT to concatenate the postcode and city.
Afterwards you just need to define a target, save, and deploy.
Example 3 – Regex
Another requirement we wanted to implement with a Data Flow was to apply a Regex functionality to a string. In this case we realized this with the Script Operator. As you might know this means you have to use Python. SAP provides in the documentation which libraries are available and which functions are not available within these libraries (https://help.sap.com/docs/SAP_DATA_WAREHOUSE_CLOUD/c8a54ee704e94e15926551293243fd1d/73e8ba1a69cd4eeba722b458a253779d.html?locale=en-US).
Once you open the Script Operator you get some hints on how this should be used.
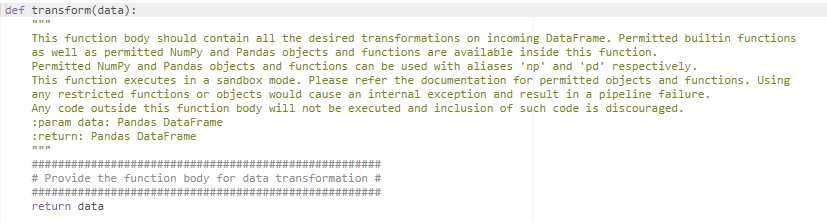
To implement our logic, we used the Pandas function str.replace() (https://pandas.pydata.org/docs/reference/api/pandas.Series.str.replace.html).
In our script we implement our function logic and make sure we return the target columns.

Currently we are not aware of any debugging possibilities and there is no syntax support or code completion. Therefore, we decided to always implement our logic ahead in an IDE which supports Python Code (VS Studio Code, Jupyter Notebooks,…). There we also use the currently supported library versions on DWC to make sure we are close to the system’s status.
At the end we define again a target and save and deploy the Data Flow.
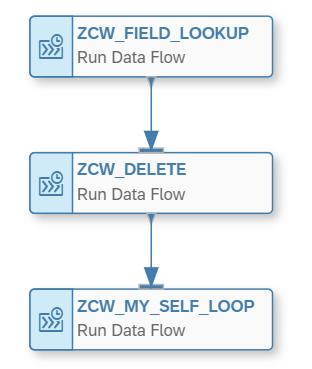
Example 4 – Myself Loop
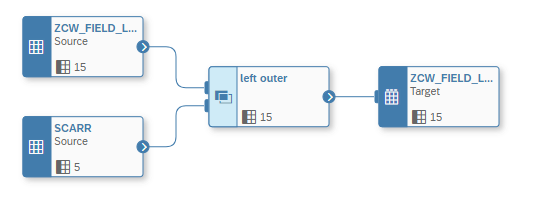
We also wanted to understand how we could implement a solution where a certain logic needs to be reapplied frequently. From BW scenarios we often applied already a so called “Myself Loop” to apply certain logic via a Transformation where the Source and the Target is the same object. This is often done for recalculation of key figures or derivations of attributes. In our example we want to derive attributes again as they might have changed (so basically apply the same logic as shown in Example 1).
To do this we created a Data Flow, where the Data Flow’s source and target are the same object. We added again a Join operator and via that we applied the same logic again.
Example 5 – Deletion in Target
In the 5th example we wanted to show how we can delete records in a target. Therefore, we will use the projection operator and the Mode we can define in the target table.
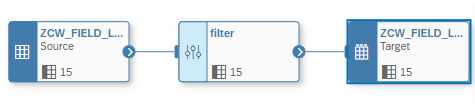
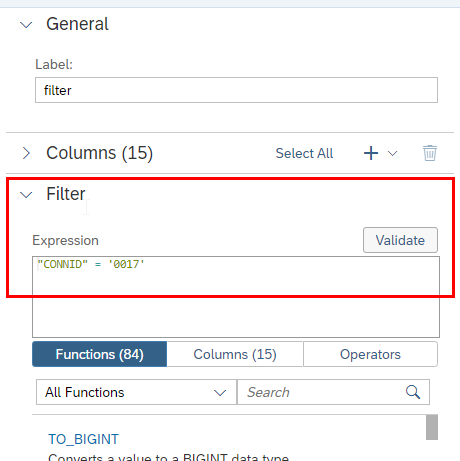
In the projection operator we define via the filter criteria which records should be deleted in the target. In our case all flights where the CONNID equals 0017.
The important step is then to adjust the Mode in the target table, in our case to “DELETE”.
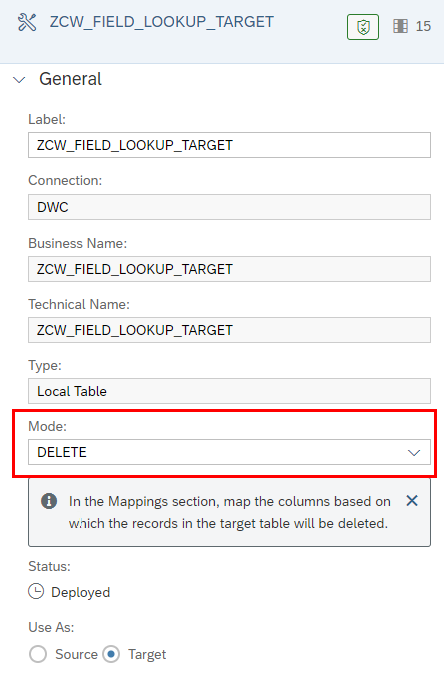
There are three different Modes:
- Append (in combination with UPSERT)
- Truncate
- Delete
How they work is described in the SAP documentation for the Target Table (https://help.sap.com/docs/SAP_DATA_WAREHOUSE_CLOUD/c8a54ee704e94e15926551293243fd1d/0fa780568975458dbd90d11d1d81f2d9.html?locale=en-US).
Example 6 – Aggregation
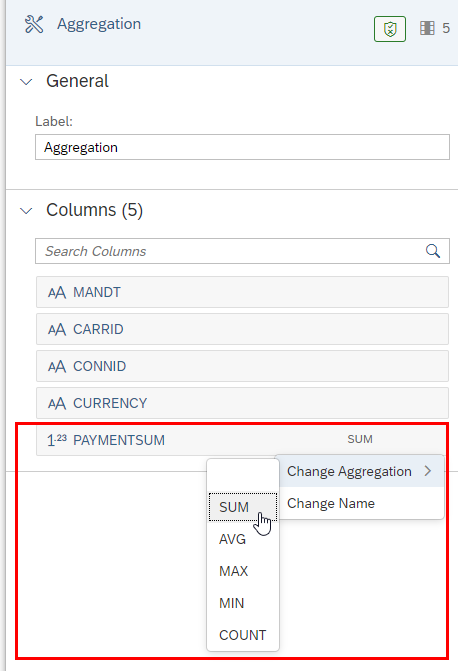
In the last example we want to show how you can aggregate Key Figures. In the first step we use a projection to only select the relevant columns and in the second step we add the Aggregation Operator and then define the aggregation.

In the Aggregation Operator you can chose between various Aggregation types which are show below.
Finally, again save and deploy and run your Data Flow.
Data Flow Execution
Data Flows can be executed in different ways. One way is to just execute it out of the Data Flow Editor. There you can also see the last time the Data Flow was executed and the status. From there you can also jump directly into the Data Flow Monitor.

The individual Data Flows can also be accessed via the Data Integration Monitor. There you have an overview of all Data Flows and some status information.
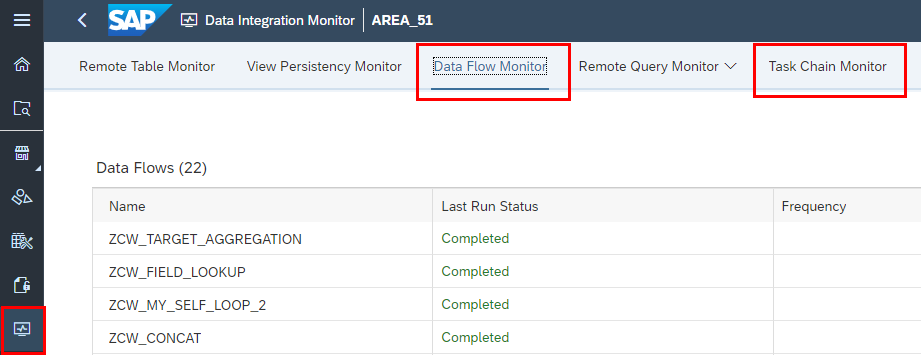
Within the Data Flow Monitor for a specific Data Flow you also see certain log information, for error solving.
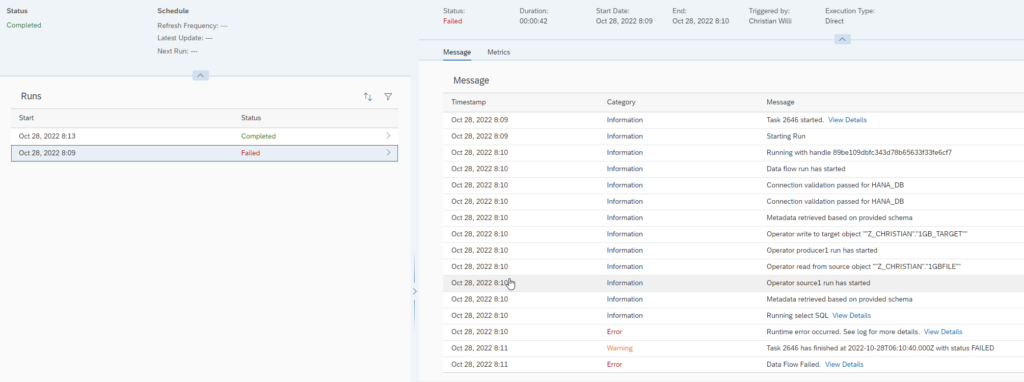
It is also possible to chain single Data Flows sequentially together in a Task Chain. These can be created within the Data Builder under the point Task Chain. Currently it is only possible to chain Data Flows sequentially and no operator like an “AND” is possible, like the operators we are used from Process Chains in BW.
Conclusion & Outlook
In this Blog we wanted to showcase certain very simple requirements and how they can be realized currently in DWC. Of course, there are also other solutions already available (e.g., Working with View to transform data) in DWC. We think that certain basic requirements can be solved in DWC already with Data Flows when it comes to transforming data.
In the next step we want to see how Data Flow performs when we upload a 1GB CSV file into DWC and transform these records with similar use cases we have shown above. Additionally, we also show how a Data Flow performs when a logic is applied in the Script operator in comparison to using Views with built in SQL functions.